
简介
文本分类📖在文本处理中是很重要的一个模块,它的应用也非常广泛,比如:新闻分类、简历分类、邮件分类、办公文档分类、区域分类等诸多方面,还能够实现文本过滤,从大量文本中快速识别和过滤出符合特殊要求的信息。核心方法为首先提取分类数据的特征,然后选择最优的匹配,从而分类。
通常来讲,文本分类任务是指在给定的分类体系中,将文本指定分到某个或某几个类别中,被分类的对象有短文本,例如句子、标题、商品评论等等,长文本如文章等。分类体系一般人工划分,例如:1)政治、体育、军事 2)正能量、负能量 3)好评、中性、差评。此外,还有文本多标签分类,比如一篇博客的标签可以同时是:自然语言处理,文本分类等。因此,对应的分类模式可以分为:二分类、多分类以及多标签分类。

文本分类的主要任务
情感分析⭐️:分析人们在文本数据(如产品评论、电影评论和推特)中的观点,并提取他们的极性和观点。可以是二分类问题也可以是多分类问题,二元情感分析是将文本分为正类和负类,而多类情感分析则侧重于将数据分为细粒度的标签或多层次的强度。
新闻分类⭐️:新闻分类系统可以帮助用户实时获取感兴趣的信息。基于用户兴趣的新闻主题识别和相关新闻推荐是新闻分类的两个主要应用。
主题分析⭐️:主题分析试图通过识别文本的主题从文本中自动获得意义。主题分类的目标是为每个文档分配一个或多个主题,以便于分析。
问答系统⭐️:有两种类型的问答系统:提取式和生成式。抽取式
QA可以看作是文本分类的一个特例。给定一个问题和一组候选答案,根据问题需要将每个候选答案正确分类。自然语言推理⭐️:
NLI,也称为文本蕴含识别(RTE),预测一个文本的含义是否可以从另一个文本中推断出来。特别是,一个系统需要给每对文本单元分配一个标签,比如蕴涵、矛盾和中立。
文本分类的主要方法
基于规则特征匹配的方法(如根据“喜欢”,“讨厌”等特殊词来评判情感,但准确率低,通常作为一种辅助判断的方法)。
基于传统机器学习的方法(特征工程 + 分类算法)。
基于深度学习的方法(词向量 + 神经网络)。
GLUE 任务与数据集
GLUE 数据集:通用语言理解评估 General language Understanding Evaluation: GLUE 基准是一组各种 NLP 文本任务。大多数 GLUE 数据集已经存在多年,而 GLUE 将它们收集在一起的目的是:
为这些数据集建立统一的训练集、验证集、测试集拆分标准。
GLUE不给测试集打标签,用户必须将测试结果上传到GLUE服务器进行评估(但是提交次数有限)。
GLUE 基准包含以下数据集:
Multi-Genre Natural Language Inference: MNLI⭐️:大规模的、众包的蕴含分类任务。给定一对句子,其目标是预测第二句相对于第一句是蕴含句entailment、矛盾句、还是中性句。Quora Question Pairs: QQP⭐️:一个二元分类任务。给定一对Quora上的两个问题,其目标是预测它们在语义上是否等价。Question Natural Language Inference: QNLI⭐️:斯坦福Question Answering数据集的一个转换为分类任务的版本。正类样本由问题和正确答案组成,负类样本由问题和非正确答案组成,其中非正确答案来自于同一段文本。Stanford Sentiment Treebank: SST-2⭐️:一个二元单句分类任务。其数据集从电影评论中提取的句子组成,由人类对其进行二元情感标注。Corpus of Linguistic Acceptability: CoLA⭐️:一个二元单句分类任务。其目标是预测一个英语句子是否在语法上可接受的。Semantic Textual Similarity Benchmark: STS-B⭐️:一个句子相似度多元分类任务。其数据集从新闻标题和其它数据源提取的句子对,通过人工来标记一对句子在语义上的相似得分(1分到5分)。Microsoft Research Paraphrase Corpus: MRPC⭐️:一个句子相似度二元分类任务。从在线新闻数据源抽取的句子对,由人工标记一对句子是否语义上相等。Recognizing Textual Entailment: RTE⭐️:类似MNLI的二元蕴含关系任务,但是RTE数据集规模更小。
FastText 😊
论文:https://arxiv.org/abs/1607.01759
代码:https://github.com/facebookresearch/fastText
FastText是 Facebook 于2016年开源的一个词向量计算和文本分类工具,在文本分类任务中,FastText(浅层网络)往往能取得和深度网络相媲美的精度,却在训练时间上比深度网络快许多数量级。
FastText是一个快速文本分类算法,其具有两大优点:
FastText在保持高精度的情况下加快了训练速度和测试速度FastText不需要预训练好的词向量,FastText会自己训练词向量FastText两个重要的优化:Hierarchical Softmax、N-gram
Word2Vec
🎈 在我们深入研究 FastText 之前,让我们快速回顾一下 Word2Vec是什么,通过 Word2Vec,我们训练一个具有单一隐藏层的神经网络,根据其上下文(邻近的词)预测目标词。我们的假设是,一个词的含义可以通过它周围出现的词来推断。实际上,在训练时,你可以使用两种不同的网络架构来实现: CBOW 和 Skip-Gram。
Continuous Bag of Words: 根据背景词预测中心词。

Skip-Gram: 根据中心词预测背景词。

通过这种方法所学到的词向量表征具有一些有趣的特性,例如这个流行的例子:

🎈 word2vec 中提供了两种针对大规模多分类问题的优化手段, Negative sampling 和 Hierarchical softmax。
Negative sampling通过只更新少量负类词的词向量,从而减轻了计算量。Hierarchical softmax将词库表示成前缀树,从树根到叶子的路径可以表示为一系列二分类器,一次多分类计算的复杂度从 $|V|$ 降低到了树的高度 $log_2 |V|$ 。
🎈 FastText 的核心思想就是:将整篇文档的词及 n-gram 向量叠加平均得到文档向量,然后使用文档向量做 softmax 多分类,其本质上就是传统的词袋法,即将文档看成一个由词构成的集合。
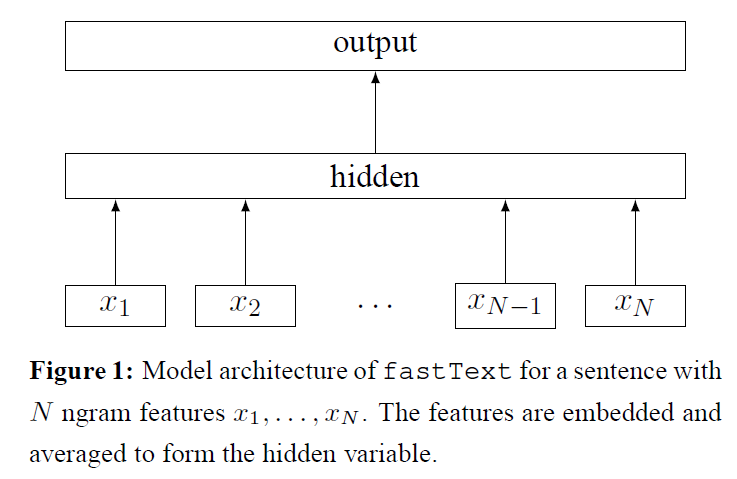
🎈 基于词袋的方法一个明显的缺点是:
我不喜欢这类电影,但是喜欢这一个。
我喜欢这类电影,但是不喜欢这一个。
这样的两个句子经过词向量平均以后已经送入单层神经网络的时候已经完全一模一样了,分类器不可能分辨出这两句话的区别,只有添加 n-gram 特征以后才可能有区别。因此,在实际应用的时候需要对数据有足够的了解,然后再选择模型。
🎈 对于文本长且对速度要求高的场景,Fasttext 是 Baseline 首选。同时用它在无监督语料上训练词向量,进行文本表示也不错。不过想继续提升效果还需要更复杂的模型。
模型结构和代码
模型输入:
[batch_size, seq_len]embedding层:随机初始化, 词向量维度为embed_size:[batch_size, seq_len, embed_size]求所有
seq_len个词的均值:[batch_size, embed_size]全连接 +
softmax归一化:[batch_size,num_class]
1 | class FastText(nn.Module): |
TextCNN 😊
论文:https://arxiv.org/abs/1408.5882
代码:https://github.com/yoonkim/CNN_sentence
TextCNN 是 Yoon Kim 在 2014 年提出的模型,开创了用 CNN 编码 n-gram 特征的先河。
详细过程:
Embedding:第一层是图中最左边的 $5 \times 3$ 的句子矩阵,每行是词向量,维度为 $3$,这个可以类比为图像中的原始像素点。Convolution:然后经过filter_sizes=(2,3,4)的一维卷积层,每个filter_size有 $2$ 个输出channel。MaxPolling:第三层是一个1-max pooling层(因为是时间维度的,也称max-over-time pooling),这样不同长度句子经过pooling层之后都能变成定长的表示。Full Connection and Softmax:最后接一层全连接的softmax层,输出每个类别的概率。
在 TextCNN 的实践中,有很多地方可以优化:
filter_sizes🤗:这个参数决定了抽取n-gram特征的长度,这个参数主要跟数据有关,平均长度在 $50$ 以内的话,用 $10$ 以下就可以了,否则可以长一些。在调参时可以先用一个尺寸grid search,找到一个最优尺寸,然后尝试最优尺寸和附近尺寸的组合。n_filters🤗:这个参数会影响最终特征的维度,维度太大的话训练速度就会变慢。这里在 $100-600$ 之间调参即可。CNN的激活函数🤗:可以尝试ReLU、tanh。Regularization🤗:指对CNN参数的正则化,可以使用dropout或L2,但能起的作用很小,可以试下小概率的dropout。Pooling方法🤗:根据情况选择mean、max、k-max pooling,大部分时候max表现就很好,因为分类任务对细粒度语义的要求不高,只抓住最大特征就好了。Embedding🤗:中文可以选择char或word级别的输入,也可以两种都用,会提升些效果。如果训练数据充足($10w+$),也可以从头训练。
TextCNN是很适合 中短文本场景 的强Baseline,但 不太适合长文本,因为卷积核尺寸通常不会设很大,无法捕获长距离特征。同时max-pooling也存在局限,丢失了文本的结构信息,因此很难去发现文本中的转折关系等复杂模式。TextCNN和传统的n-gram词袋模型本质是一样的,它的好效果很大部分来自于词向量的引入,解决了词袋模型的稀疏性问题。
模型结构和代码
1 | class TextCNN(nn.Module): |
TextRNN 😊
RNN
循环神经网络(Recurrent Neural Network,RNN)是一类具有短期记忆能力的神经网络。在循环神经网络中,神经元不但可以接受其它神经元的信息,也可以接受自身的信息,形成具有环路的网络结构。
长程依赖问题
虽然简单循环网络理论上可以建立长时间间隔的状态之间的依赖关系,但
是由于梯度爆炸或消失问题,实际上只能学习到短期的依赖关系。这样,如果时刻 $t$ 的输出 $y_t$ 依赖于时刻 $k$ 的输入 $x_k$,当间隔 $t−k$ 比较大时,简单神经网络很难建模这种长距离的依赖关系,称为长程依赖问题(Long-Term Dependencies Problem)。
LSTM
为了改善循环神经网络的长程依赖问题,一种非常好的解决方案是引入门控机制来控制信息的累积速度,包括有选择地加入新的信息,并有选择地遗忘之前累积的信息。
长短期记忆(Long Short-Term Memory,LSTM)网络[Gers 等人; Hochreiter等人,2000; 1997] 是循环神经网络的一个变体,可以有效地解决简单循环神经网络的梯度爆炸或消失问题。
LSTM的关键在于细胞的状态 $C_t$ 和穿过细胞的线,细胞状态类似于传送带,直接在整个链上运行,只有一些少量的线性交互,信息在上面流动保持不变会变得容易。
LSTM 网络引入门控机制(Gating Mechanism)来控制信息传递的路径。LSTM网络中的“门”是一种“软”门,取值在 $(0, 1)$ 之间,表示以一定的比例运行信息通过。
遗忘门
遗忘门 $f_{t}$ 控制上一个时刻的内部状态 $c_{t−1}$ 需要遗忘多少信息。
输入门
输入门决定让多少新的信息加入到当前的 $C_t$ 中来。实现这个需要两个步骤:
- 首先计算出输入门 $i-t$ 和候选记忆细胞状态。
- 结合遗忘门 $f_t$ 和输入门 $i_t$ 来更新记忆单元 $C_t$
输出门
最终,我们需要确定输出什么值,这个输出将会基于我们的细胞的状态,但是也是一个过滤后的版本。首先,我们通过一个 sigmoid 层来确定细胞状态的哪些部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个 $[-1,1]$ 之间的值)并将它和sigmoid 门的输出相乘。
GRU
在 LSTM 中引入了三个门函数:输入门、遗忘门和输出门来控制信息的传递,由于输入门和遗忘门是互补关系,具有一定的冗余性,GRU 网络
直接使用一个门来控制输入和遗忘之间的平衡,在 GRU 模型中只有两个门:分别是更新门和重置门。
图中的 $z_{t}$ 和 $r_{t}$ 分别表示更新门和重置门。更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。重置门控制前一状态有多少信息被写入到当前的候选状态 $\tilde{h}_{t}$ 上,重置门越小,前一状态的信息被写入的越少。
LSTM 和 GRU 都是通过各种门函数来将重要特征保留下来,这样就保证了在 long-term 传播的时候也不会丢失。此外 GRU 相对于 LSTM 少了一个门函数,因此在参数的数量上也是要少于LSTM 的,所以整体上 GRU 的训练速度要快于 LSTM 的。
Attention
Attention 计算:
其中 $H$ 为每个时刻得到的隐藏状态, $u$为 context vector,随机初始化并随着训练更新,最后得到句子表示 $rep$,再进行分类。
模型结构和代码
1 | class RNNAttention(nn.Module): |
参考链接
- https://arxiv.org/abs/1607.01759
- https://arxiv.org/abs/1408.5882
- https://ai.tencent.com/ailab/media/publications/ACL3-Brady.pdf
- https://dl.acm.org/doi/10.5555/2886521.2886636
- https://www.aclweb.org/anthology/N16-1174.pdf
- https://zhuanlan.zhihu.com/p/266364526
- https://cloud.tencent.com/developer/article/1389555
- https://www.cnblogs.com/sandwichnlp/p/11698996.html
- https://github.com/jeffery0628/text_classification
- https://zhuanlan.zhihu.com/p/349086747
- https://zhuanlan.zhihu.com/p/35457093
- https://www.pianshen.com/article/4319299677/
- https://www.zhihu.com/question/326770917/answer/698646465

